

Introduction
Since ChatGPT emerged, the concepts of large language models (LLMs), generative AI, and foundation models have rapidly permeated our lives, work, and research domains, creating numerous new opportunities. However, these technologies also come with critical limitations and risks. Primarily:
- Hallucination: LLMs sometimes make up facts or events that are not based on real data, leading to incorrect or missleading answers.
- Opaqueness: It can be difficult to trace where LLMs get their information or how they combine sources to generate responses.
- Staleness: LLMs are not frequently updated due to high computational and energy costs, which means they often lack the latest information.
- Incompleteness: LLMs provid answers essentially based on a conditional probabilistic model and may miss important details or fail to list all relevant information.
To address these issue, LLMs are increasingly combined with complementary technologies such as search engines (SEs) and knowledge graphs (KGs). This combination offers a promising way to mitigate the weaknesses of each individual system while amplifying their strengths.
In this blog, I will summarize a recent survey paper titled Large Language Models, Knowledge Graphs, and Search Engines: Answering Questions at a Crossroads by Aidan Hogan, Xin Luna Dong, Denny Vrandečić, and Gerhard Weikum. The paper delves into the strengths, weaknesses, and potential synergies of SEs, KGs, and LLMs, providing valuable insights into their alignment with user needs and exploring promising directions for future research.
A Brief Overview of KGs, SEs and LLMs
First, let’s explore what these three techniques are and how they appear when used in practice:
- KGs: These are structured representations of interconnected data that enable reasoning, precise querying, and integration of diverse datasets.
- SEs: These are information retrieval systems that index and rank vast amounts of textual content to match user queries effectively.
- LLMs: These are deep learning models trained on vast text corpora, capable of generating human-like text, answering questions, and synthesizing information.
The following image illustrates how these technologies handle the same question: “What are the 10 most populous cities in the world?”
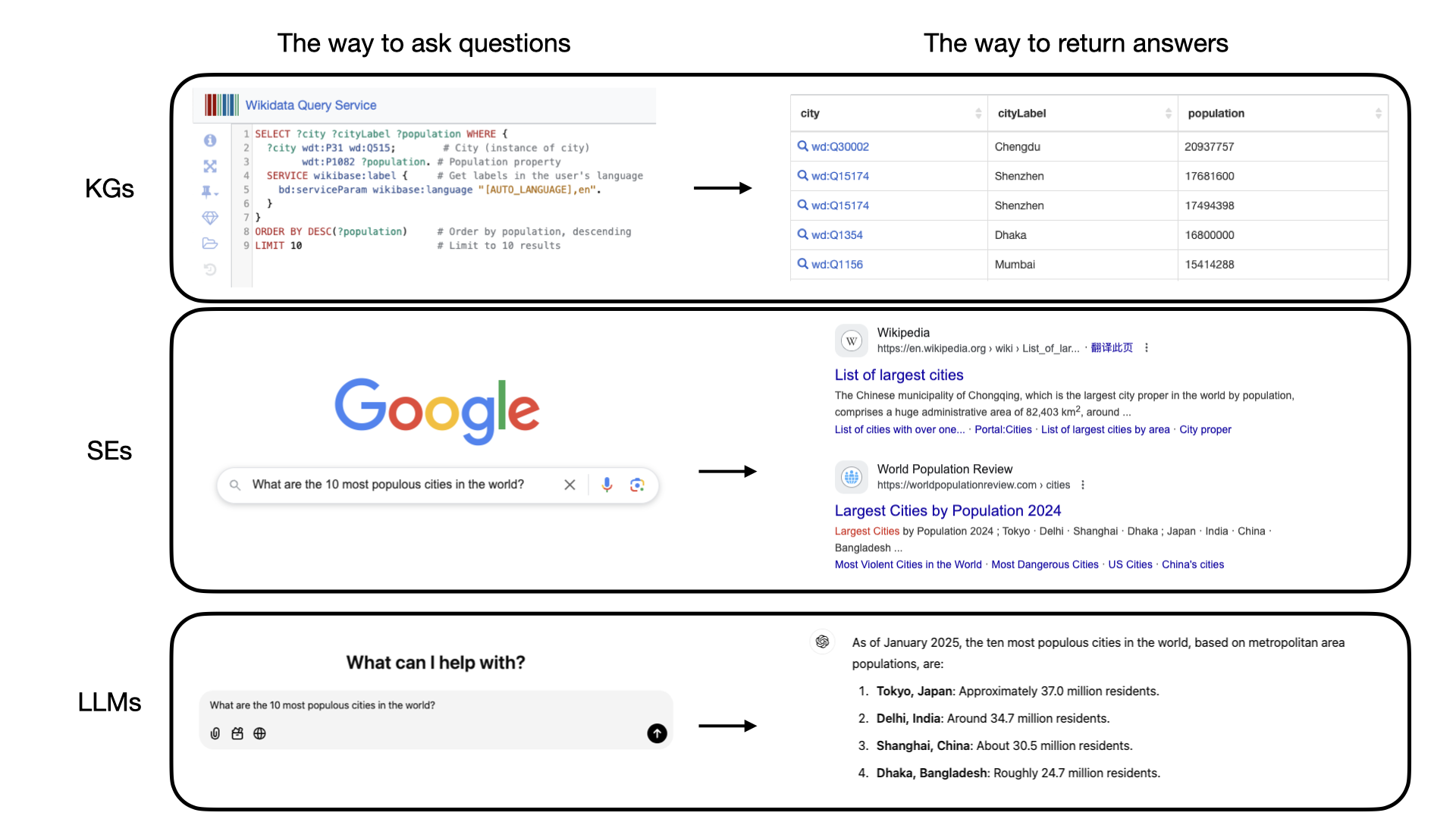
- KGs: Users interact through structured queries (e.g., SPARQL) to retrieve precise, structured data from the graph, such as city names and populations.
- SEs: Users input natural language queries and receive ranked results from websites, often leading to pages containing relevant data.
- LLMs: Users engage conversationally and receive synthesized answers directly in natural language, often including approximations or context-based explanations.
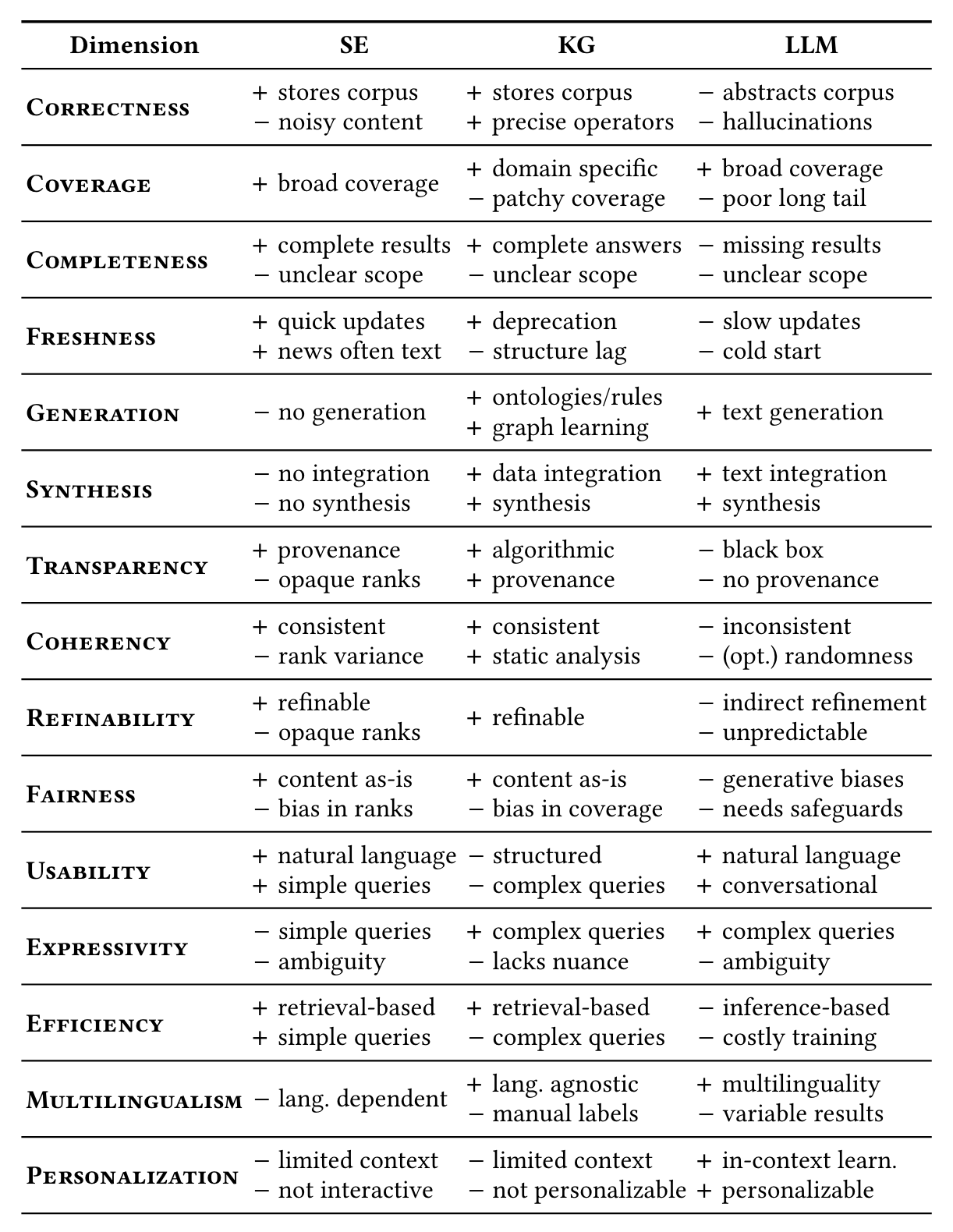
Pros and Cons of SEs, KGs and LLMs
These approaches highlight their unique pros and cons.
Pros:
- LLMs: Broad contextual understanding, generative capabilities, and interactive interfaces.
- KGs: Precision, transparency, and ability to handle complex, multi-hop queries.
- SEs: Scalability, freshness, and access to diverse web content.
Cons:
- LLMs: Prone to hallucination, opacity, and inefficiency.
- KGs: Limited scope, manual curation requirements, and difficulty with nuanced queries.
- SEs: Dependence on textual content, limited synthesis capabilities, and opaque ranking mechanisms.
This comparison reminds me of the keynote speech from ISWC 2023 by Prof. Gerhard Weikum, which provides an intuitive analogy to differentiate these technologies. Prof. Weikum compared KGs, SEs, and LLMs to types of fruit desserts:
- KGs are like a fruit platter: They offer a limited selection of fruit (coverage is limited compared to the other two techniques), but the fruit is neatly arranged. If you want mango, you can find it precisely and quickly (correctness).
- SEs are like a fruit salad: They contain a wide variety of fruits but are all mixed together. While there’s more to choose from, good luck finding the mango easily amidst everything else.
- LLMs are like a fruit juice: They are delightful in flavor and texture, and many people prefer them. They potentially include everything, but you have no idea what’s really inside—and no way to confirm whether there’s mango.
For a more comprehensive and well-organized analysis of the finer-grained pros and cons of these technologies, refer to the original paper.
User Needs
However, how the pros and cons affect the end user depend heavily on the users’ demands.
There are some types of queries that frequently asked from users:
- Factual Queries: Simple or complex factual needs.
- Exploratory Queries: Seeking understanding of unfamiliar topics.
- Dynamic and Analytical Queries: Real-time data or computational results.
- Planning and Advice: Guidance for actionable decisions or philosophical questions.
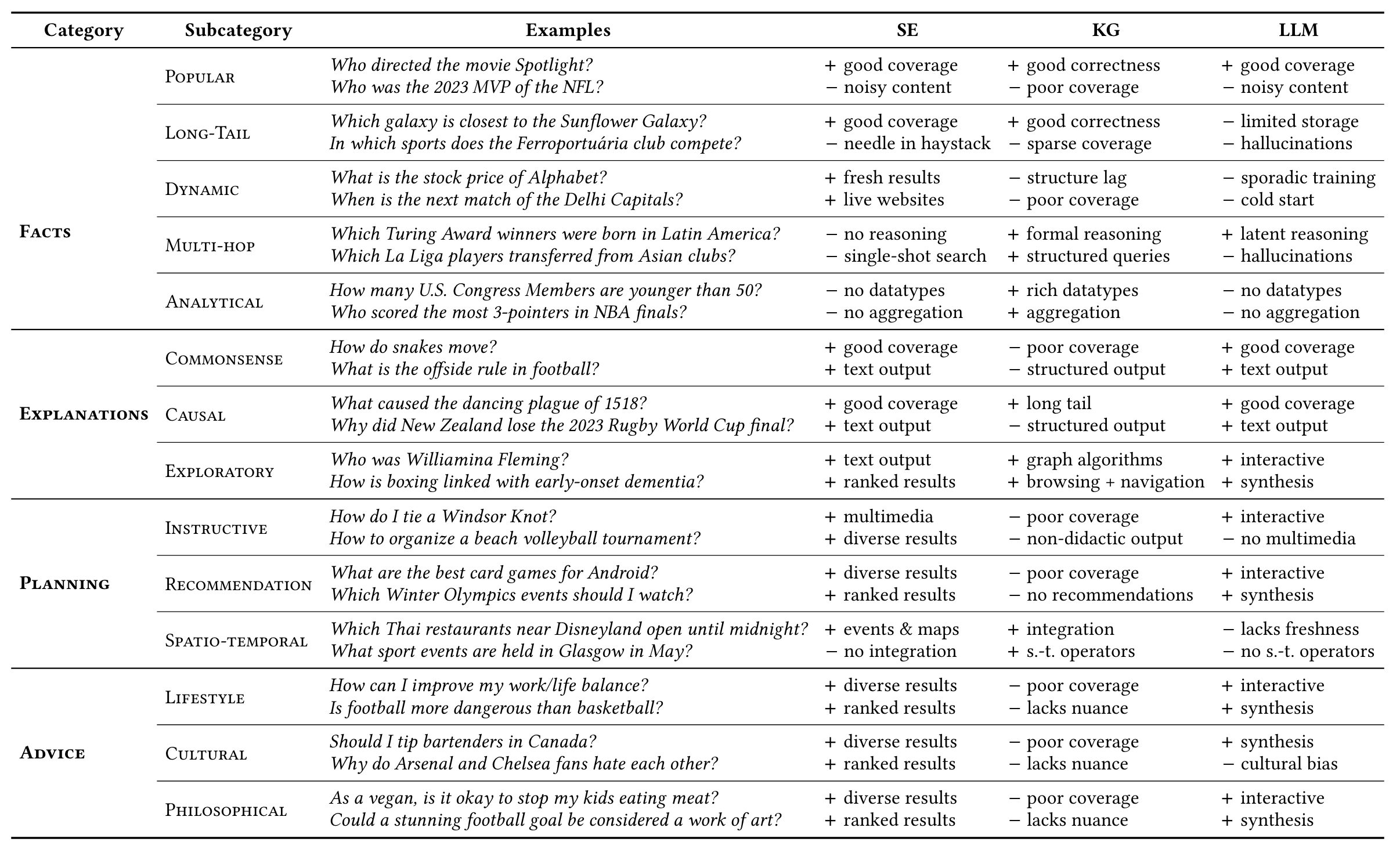
KGs are excellent for factual queries, particularly complex ones requiring precision and structured reasoning. They are efficient and transparent, making them reliable for analytical tasks. However, their usability is limited for non-experts, and they struggle with exploratory queries, dynamic updates, and subjective tasks like planning or advice. Their curated nature also limits coverage for long-tail topics.
SEs excel at addressing factual and dynamic queries with their broad coverage and real-time updates. They are highly usable and effective for exploratory queries, providing ranked results from diverse sources. However, they lack the ability to synthesize information spread across multiple documents, making complex analytical tasks difficult. They also provide limited support for nuanced or subjective planning and advice queries.
LLMs are highly effective for subjective and nuanced queries, such as planning, advice, and explanations, while also handling exploratory queries through interactive conversations. They can synthesize diverse information to address complex factual needs. However, they struggle with accuracy, often providing unverifiable or hallucinated answers. They are less reliable for analytical queries and lack transparency, making them less suitable for tasks requiring clear provenance or highly precise reasoning.
Research Direction
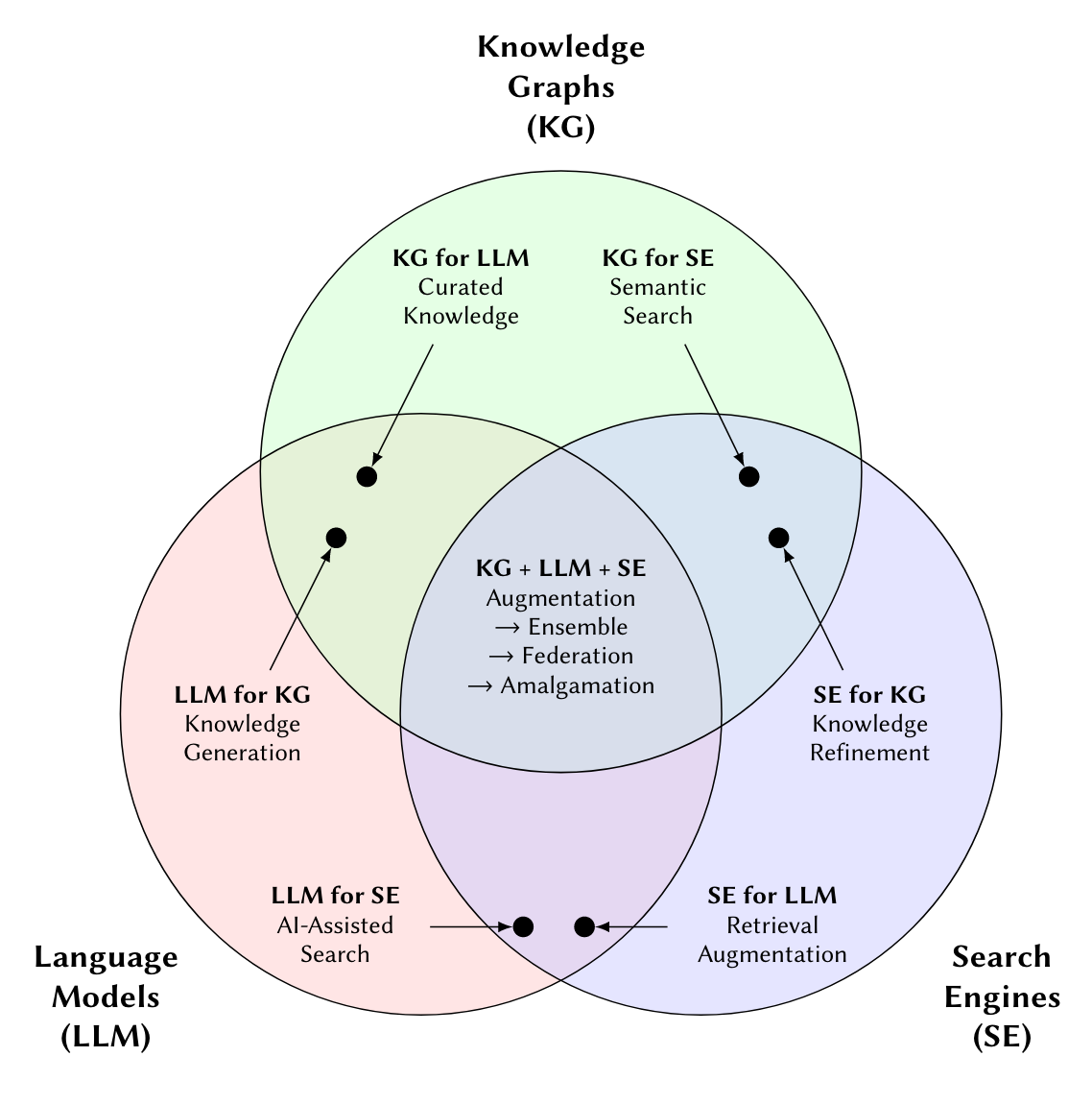
There are many research directions that combine techniques to improve the overall performance:
- KG for SE (Semantic Search): Use KGs to enhance semantic search by providing structured information (e.g., knowledge panels) to refine results, improve query understanding, and support complex multi-hop queries.
- KG for LLM (Curated Knowledge): Integrate curated knowledge from KGs to augment LLMs, improving accuracy for factual and complex queries, and reducing hallucinations. KGs can also verify LLM outputs during post-processing.
- SE for KG (Knowledge Refinement): Leverage SEs to refine and expand KGs by identifying and incorporating new facts, ensuring freshness, and validating information through diverse web sources.
- SE for LLM (RAG): Implement Retrieval-Augmented Generation (RAG) by using SEs to supply real-time and relevant context to LLMs during inference, improving freshness and accuracy for long-tail queries.
- LLM for SE (AI-assistant Search): Enhance SE functionality with LLMs for conversational search, better query generation, and improved relevance scoring. LLMs can also summarize and synthesize information from top-ranked SE results.
- LLM for KG (Knowledge Generation): Employ LLMs to fill gaps in Knowledge Graphs, generate new knowledge, and enhance the representation of nuanced facts. LLMs can extend KGs with facts about long-tail entities and support reasoning for complex knowledge.
Ideally, we aim for systems that provide Internet-scale coverage and real-time freshness, deliver precise answers with clear and user-friendly explanations of their sources, and seamlessly support a wide range of tasks—from simple fact lookups to complex analytical queries and personalized advice—while maintaining low computational cost. This require to combine all three techniques KG+SE+LLM in the future.
{kind=link}