

Robust Knowledge Extraction from Large Language Models using Social Choice Theory
If you’ve experimented with Large Language Models (LLMs) like ChatGPT, you might have noticed that asking the same question multiple times often produces different answers. While this variability may be acceptable or even desirable in creative writing tasks, it raises concerns in high-stakes domains like medicine, where precision and consistency are critical.
In our paper, presented at AAMAS 2024, we propose a novel method to enhance the robstness of LLM’s query results. By applying techniques from social choice theory, we combine multiple outputs from repeated queries into a single, more reliable answer. Our work focuses on ranking queries in diagnostic scenarios, such as mdical diagnosis, and evaluate how well these techniques improve robustness.
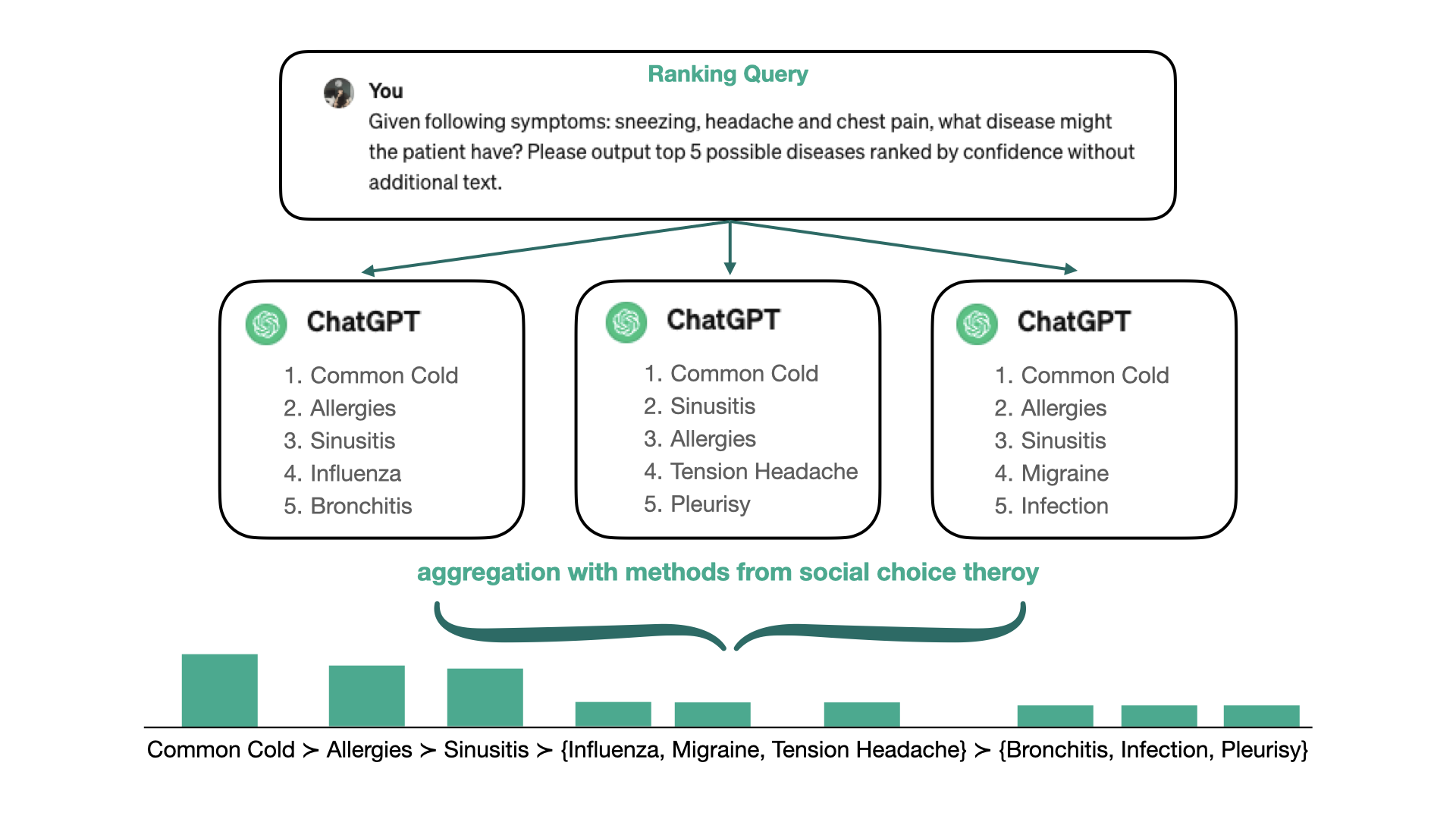
Understanding the Problem: Why Are LLM Outputs Inconsistent?
LLMs generate text by predicting the next word in a sequence based on probabilities. For example, given a question, the model generates potential answers by sampling words from a probability distribution. This process is inherently stochastic: the same query can lead to different answers if the model is run multiple times.

The level of randomness is controlled by a parameter called temperature:
- A low temperature (e.g. $t=0$) makes the process deterministic, always selecting the most likely token.
- A high temperature increases randomness, favoring less probable words and producing more varied (maybe more creative) outputs.
While setting $t=0$ can eliminate variability, the deterministic answers provided by greedy search will be somewhat random because it corresponds to some local optimum found by LLMs. It can potentially overlook better alternative answers that lie outside the chosen path.
Our Approach: Aggregating Answers Through Social Choice Theory
Instead of trying to eliminate randomness, our method embraces it. We query the LLM multiple times for the same question and aggregate the resulting rankings using Partial Borda Weighting (PBW), a technique from social choice theory. This allows us to harness the diversity of the outputs to form a robust and reliable consensus.
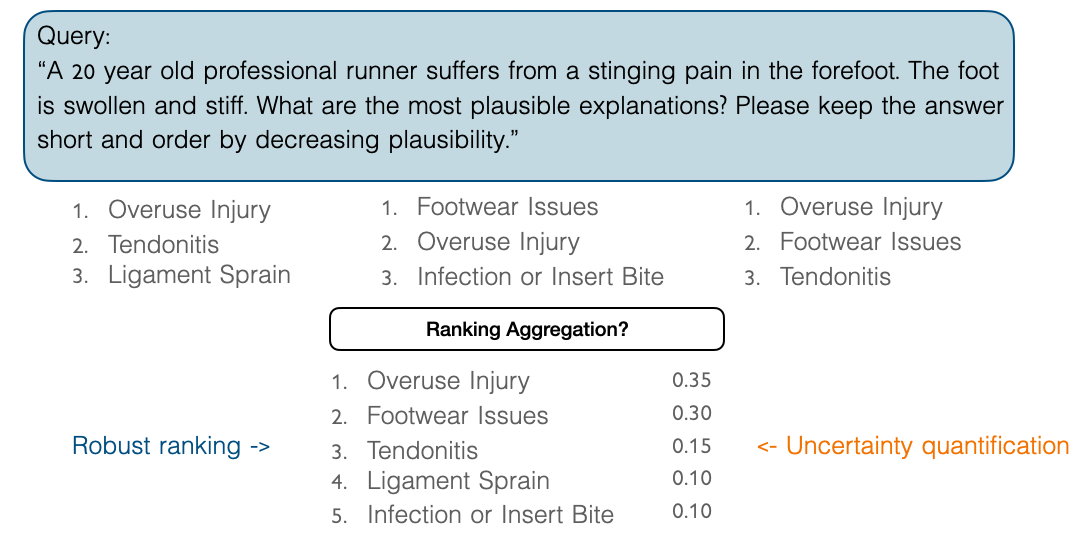
What Is Social Choice Theory?
Social choice theory is the study of methods for aggregating individual preferences into a collective decision. It’s widely used in voting systems, where the goal is to determine a winner based on ranked preferences. In our case, the “voters” are the repeated outputs from the LLM, and their “preferences” are the ranked lists of plausible answers.
PBW assigns scores to options based on their relative ranking in each output. For example:
- If “Overuse Injury” consistently ranks higher than “Tendonitis” across queries, it will receive a higher aggregated score.
- PBW handles ties and partial preferences gracefully, ensuring that all plausible answers contribute to the final ranking.
Why PBW?
The key reason is that we cannot request a comprehensive ranking of all possible answers from LLMs—either because the number of potential answers is too large or because the complete list of answers is simply unknown.
From a theoretical perspective,, PBW satisfies several desirable properties for aggregating rankings:
- Consistency: Combining results from different subsets of rankings yields the same outcome as aggregating the full set.
- Neutrality: The identity of the options doesn’t influence the results.
- Faithfulness: If one option consistently dominates others, it will rank highest.
Experimental Results: Proving Robustness
We tested our method on diagnostic tasks in three domains: medicine, finance, and manufacturing. For example, in a medical scenario, we queried the LLM about the causes of symptoms like foot pain or swelling. Without aggregation, repeated queries often yielded inconsistent rankings. PBW, however, produced stable and robust rankings.
We evaluated robustness using statistical measures like Kendall’s Tau and Spearman’s Rank Correlation. Our results showed that:
- PBW significantly outperformed baselines in both high and low uncertainty scenarios.
- Aggregating even a small number of queries led to substantial improvements in robustness.
Looking Ahead: Applications and Future Work
Our approach has broad implications:
- Healthcare: Improve diagnostic reliability when using LLMs for clinical decision support.
- Engineering: Enhance fault diagnosis in manufacturing systems.
- Research Assistants: Increase consistency in answering technical queries.
Future directions include exploring whether our method can withstand adversarial queries and extending it to other types of uncertainty, such as syntactic variations or domain-specific knowledge gaps.
Conclusion
LLMs are powerful tools, but their stochastic nature can limit their reliability in critical applications. By combining insights from social choice theory with the strengths of LLMs, we’ve developed a method that makes knowledge extraction more robust and trustworthy. We hope our work inspires further research into making AI systems more reliable for high-stakes domains.
If you’d like to learn more, please refer to our paper:
Nico Potyka, Yuqicheng Zhu, Yunjie He, Evgeny Kharlamov, and Steffen Staab. 2024. Robust Knowledge Extraction from Large Language Models using Social Choice Theory. In Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems (AAMAS ‘24). International Foundation for Autonomous Agents and Multiagent Systems, Richland, SC, 1593–1601.
{kind=link}